Tasks
NTCIR15 QA Lab-PoliInfo-2 Dataset
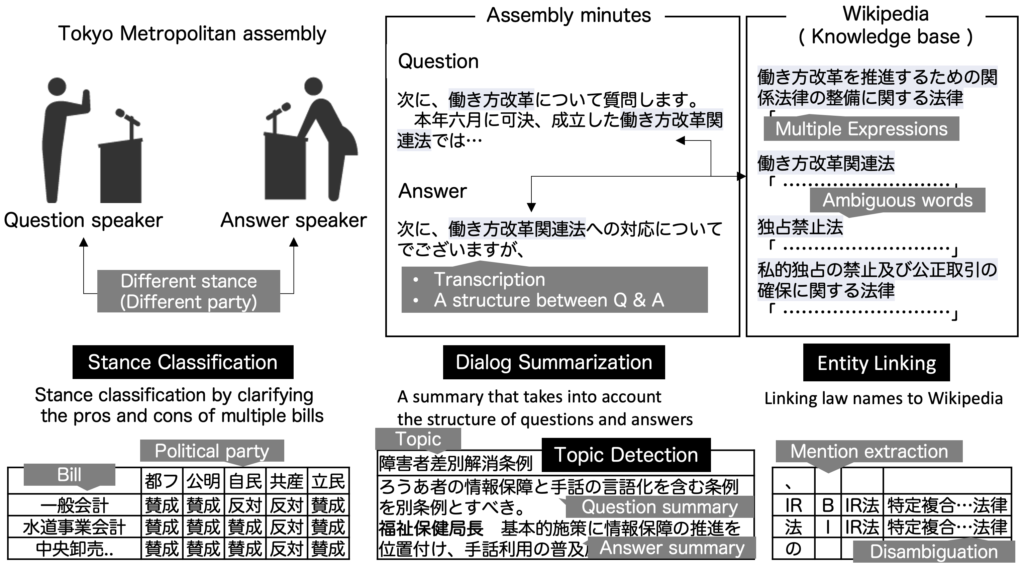
NTCIR15 QA Lab-PoliInfo2 では、議会会議録を用いて、3つ4つのタスクを設計しました。図に議会会議録と4つのタスクの関係を示します。
 2020年3月18日NLP2020 F3-2 「NTCIR-15 QA Lab-PoliInfo2 のタスク設計」(発表スライドPDF)
2020年3月18日NLP2020 F3-2 「NTCIR-15 QA Lab-PoliInfo2 のタスク設計」(発表スライドPDF)
2020年3月18日NLP2020 F3-2 「NTCIR-15 QA Lab-PoliInfo2 のタスク設計」(発表スライドPDF)
Stance classification task
Stance classification taskは、政治家の発言から、政治家の立場を推定することを目的としています。 PoliInfo2 では、東京都議会における議員の発言を対象として、会派の各議案に対する賛成・反対の立場を推定します。 入力は、都議会会議録(定例会/委員会)、出題ファイル(発言者の会派、会派に対する賛否を埋める欄などが含まれる)であり、出力は、各議案に対する会派の立場(賛成 or 反対)です。Dialog summarization task
Dialog summarization taskは、地方議会における対話の構造を考慮しながら、自動要約することを目的としています。 PoliInfo2 では、対話の構造として、議会における「議員の質問」と「知事側の答弁」の対話構造を踏まえつつ、自動要約を行います。 入力は、都議会会議録(定例会)と出題ファイル(発言者名、要約文字数など)であり、出力は人手で作成された「都議会だより」と同じ構造の要約結果です。Entity linking task
Entity linking task は、政治家の発言に含まれる政治用語を対象として、表記揺れや曖昧性の問題を解決しながら、発言の根拠となる記事や一次情報と結びつけることを目的としています。 PoliInfo2 では、政治用語の一つである「法律名」の Entity linking を行います。 入力は、議員の発言であり、出力は、「法律名」のメンション抽出と、そのメンションと法律名リスト、あるいは、Wikipediaと結びつけることです。Dialog Topic Detection
新型コロナウィルス感染症(COVID-19)による問題を解決するためは、国や地方自治体における対策を、いかに早く適切に地域住民に伝えられるかが重要である。QA Lab-PoliInfo-2では、このような事態における情報技術の可能性を検討するために、地方議会会議録を対象とした3つのタスク(Stance Classification, Dialog Summarization, Entity Linking)に続く第4のタスク(Topic Detection)を行う。
Leader board
Formal run (2020年7月6日から7月31日まで)の結果
Dialog Summarization task
| ID | Team Name | Comment | JSON | Datetime | ROUGE-1-R 内容語のマクロ平均 |
|---|---|---|---|---|---|
| 189 | JRIRD | 外部の学習データを追加。 | download | 2020-07-28 10:30:00 | 0.3208 |
| 185 | JRIRD | データ更新に対応。プログラムのバグ修正。 | 2020-07-27 10:30:03 | 0.2980 | |
| 195 | JRIRD | 不要な部分の出力を抑止。 | download | 2020-07-29 10:15:10 | 0.2980 |
| 216 | nukl | 文選択だけでなく,文短縮にもランダムフォレストを適用.それ以外はID187と同じ. | download | 2020-07-31 23:38:18 | 0.2581 |
| 148 | TO | NLP2020で発表した結果 | download | 2020-07-09 11:35:41 | 0.2436 |
| 215 | Forst | サブストリング選択手法の見直し | download | 2020-07-31 22:27:36 | 0.2410 |
| 187 | nukl | ID161と同じ手法.再学習とバッグの修正. | download | 2020-07-27 21:25:17 | 0.2387 |
| 161 | nukl | ID148と同様の手法だが,学習データを前回のものから,PoliInfo2 のSegmentedなデータを使ったものに変更. | download | 2020-07-15 14:40:45 | 0.2274 |
| 172 | nukl | 161から、要約元の範囲推定の手法を変更。 | download | 2020-07-24 14:31:25 | 0.2198 |
| 200 | Forst | バグ修正 | download | 2020-07-29 23:24:24 | 0.2145 |
| 194 | Forst | サブストリング分割手法の見直しと、セグメンテーションのバグ修正 | 2020-07-28 23:23:06 | 0.2093 | |
| 157 | TO | ID148 と同じ要約元に対し,sumy (https://pypi.org/project/sumy/) の TextRank を適用したもの. | download | 2020-07-13 14:20:58 | 0.1331 |
| 208 | wfront | 抽出型要約テスト(改良を試みたもの) | download | 2020-07-31 11:38:28 | 0.1171 |
| 151 | TO | ID148 と同じ要約元に対し,sumy (https://pypi.org/project/sumy/) の LexRank を適用したもの. | download | 2020-07-10 16:11:08 | 0.1164 |
| 181 | wfront | 抽出型要約テスト(API経由) | download | 2020-07-26 18:20:50 | 0.1058 |
| 176 | Forst | 要約すべきパッセージのいくつをいくつかのサブストリングにわけ、それらとパッセージ自体の類似度を計測した。類似度には、分散表現を用いたコサイン類似度を用いた。
類似度の高いサブストリングを抽出し、要約 とした。 | 2020-07-24 22:18:45 | 0.0782 | |
| 184 | Forst | MMRとセグメンテーションの改善 | 2020-07-26 23:04:00 | 0.0729 | |
| 211 | SKRA | Our method is extractive summarization based on EmbedRank++ WITHOUT annotated dataset. We apply it i nto summarization with Siamese BERT Network, which we originally implemented with provided minutes dataset. | 2020-07-31 13:03:38 | 0.0696 | |
| 206 | LIAT | 分類器による抽出型要約 | download | 2020-07-31 04:47:55 | 0.0555 |
Formal run 後(2020年8月1日以降の結果) |
過去のバージョン: v20200605(~7月4日の結果) |
Stance Classification task
| ID | Team Name | Comment | JSON | Datetime | Accuracy |
|---|---|---|---|---|---|
| 175 | wer99 | 会議録から賛否をルールベースで予測、ternaryを追加(非明示的なものも予測) | 2020-07-24 21:36:15 | 0.9976 | |
| 177 | wer99 | ルールベースで抽出する対象範囲を調整 | 2020-07-25 00:42:05 | 0.9976 | |
| 202 | wer99 | 手法の細かい調整、ternaryの出力範囲の見直し | 2020-07-30 21:18:45 | 0.9976 | |
| 191 | wer99 | 会議録からルールベースで賛否を予測、手法の細かい調整を行った | 2020-07-28 19:16:23 | 0.9970 | |
| 196 | wer99 | 手法の細かい調整を行った | 2020-07-29 14:24:37 | 0.9952 | |
| 186 | wer99 | 手法のチューニングを行った | 2020-07-27 20:35:06 | 0.9923 | |
| 182 | wer99 | ルールベースで抽出する対象範囲を調整、一部について機械学習手法を使用 | 2020-07-26 18:44:31 | 0.9910 | |
| 205 | Ibrk | 細部を修正 | 2020-07-31 02:05:17 | 0.9650 | |
| 180 | Ibrk | エラーを修正 | 2020-07-26 01:26:37 | 0.9644 | |
| 149 | Ibrk | 定例会の本会議から会派ごとの賛否をルールベースを用いて判定 | 2020-07-09 11:38:39 | 0.9600 | |
| 167 | Ibrk | 議案出力の方式を修正 | 2020-07-17 09:51:29 | 0.9598 | |
| 203 | knlab | バグを修正 | 2020-07-30 22:21:36 | 0.9531 | |
| 214 | knlab | 出力形式の変更 | 2020-07-31 22:03:06 | 0.9531 | |
| 199 | knlab | バグを修正 | 2020-07-29 22:52:56 | 0.9529 | |
| 158 | knlab | ルールベースと機械学習による手法 | 2020-07-13 21:06:57 | 0.9520 | |
| 160 | knlab | エラーを修正 | 2020-07-14 03:30:43 | 0.9520 | |
| 156 | akbl | 賛否を明らかにする議員の発言内容の口上部分のみをルールベースで処理したもの | 2020-07-12 21:30:45 | 0.9498 | |
| 204 | akbl | ID198とTernaryの出力を一部修正 | 2020-07-30 23:27:02 | 0.9498 | |
| 218 | akbl | ベースラインをBERTとして判定できなかったものをルールベースで処理したもの | download | 2020-07-31 23:46:51 | 0.9496 |
| 198 | akbl | 既存のルールベースで賛否が取れなかった一部会派の発言内容をBERTで二値判定したもの | 2020-07-29 22:34:40 | 0.9492 | |
| 153 | wer99 | データ更新に対応。その他、ルールベースの処理を一部改善 | 2020-07-10 22:55:31 | 0.9481 | |
| 154 | wer99 | 一部ルールの処理を修正。処理内容は前回までとほぼ同じで、主に議事録を用いたルールベースによる処理を行い、テスト時のスコアを確認するために一部を調整 | 2020-07-11 14:39:36 | 0.9461 | |
| 193 | knlab | 特徴量を変更 | 2020-07-28 23:15:17 | 0.9452 | |
| 169 | akbl | ID156のルールベースを使用せずに, BERTで議員の発言内容の口上部以外の討論文を対象に二値判定(賛成or反対)したもの | 2020-07-21 00:21:46 | 0.9399 | |
| 171 | Forst | ProsConsListTernaryについて言及の有無を表示 | 2020-07-23 18:13:33 | 0.9388 | |
| 164 | Forst | ルールベースでの手法 | 2020-07-16 11:46:49 | 0.9382 |
Formal run 後(2020年8月1日以降の結果) |
過去のバージョン: v20200605(2020年6月5日~7月4日の結果) | v20200522(2020年5月22日~6月4日の結果) | v20200310(2020年5月21日以前の結果)
Entity Linking task
| ID | Team Name | Comment | TSV | Datetime | End to End (メンション抽出+曖昧性解消)のF値 |
|---|---|---|---|---|---|
| 212 | HUHKA | 抽出した固有表現に対しfileterをかけ、201と同様に曖昧性解消を行う。 | 2020-07-31 18:51:22 | 0.6035 | |
| 201 | HUHKA | 174の辞書ベースで曖昧性解消できるものは辞書ベースで行う。それ以外のものは155の共起頻度で行う。 | 2020-07-30 20:08:16 | 0.4887 | |
| 155 | HUHKA | 曖昧性解消を共起頻度で行う | 2020-07-11 17:55:43 | 0.4747 | |
| 174 | HUHKA | 曖昧性解消を辞書ベース(e-Govの法律名・略称)で行う | download | 2020-07-24 21:18:27 | 0.4468 |
| 197 | HUHKA | 174で用いたe-Govの法律名・略称のうち、正式名称がwikipediaにあるもののみに限定 | 2020-07-29 20:30:50 | 0.4468 | |
| 150 | HUHKA | 固有表現抽出:BERT 曖昧性解消:wikipedia2vec | 2020-07-09 13:49:41 | 0.4049 | |
| 192 | HUHKA | 曖昧性解消:共起頻度+wikipedia2vec | 2020-07-28 21:54:18 | 0.3980 | |
| 217 | Forst | ID183にRNNで構成したBinary分類器の学習設定を修正/学習データ型を修正/メンション抽出でのルール修正 | 2020-07-31 23:40:15 | 0.3910 | |
| 183 | Forst | メンション抽出:既存のルールベース処理にRNNを適用して予測する処理を追加したもの | 2020-07-26 22:59:19 | 0.3656 | |
| 147 | Forst | 処理を少し修正 | 2020-07-09 00:21:32 | 0.3389 | |
| 166 | HUHKA | 曖昧性解消をwikipediaのタイトルとのexact matchで行う。一致しないものはNILを出力。 | 2020-07-16 14:25:21 | 0.3247 | |
| 146 | Forst | ルールベースで処理 | 2020-07-08 15:23:49 | 0.3089 | |
| 173 | selt | MD: BERT, ED: wikipedia2vec | 2020-07-24 14:54:04 | 0.2980 | |
| 178 | selt | MDに用いたBERTの学習epochを変更 | 2020-07-25 02:03:21 | 0.2978 | |
| 179 | selt | epoch数変更 | 2020-07-26 00:08:17 | 0.2978 | |
| 213 | selt | EDに辞書ベース手法を追加 | 2020-07-31 18:55:36 | 0.2930 | |
| 190 | nukl | 固有表現抽出を辞書ベース(日本法令索引の法律名・通称)で行う | 2020-07-28 17:52:44 | 0.2375 |
Formal run 後(2020年8月1日以降の結果) |
過去のバージョン: v20200310(~7月4日の結果) |
Information

- 2020.07.07
- 2020.07.05

- 2020.06.14

- 2020.06.08
- 2020.05.24
Schedule
2020年 07月08日本テスト開始| 2019年 09月09日 | オーガナイザーミーティング@ 福岡大学 |
|---|---|
| 2019年 09月30日 | NTCIR-15 キックオフイベント (NII, 東京) |
| 2019年10月18日(金) | 第一回説明会 @NII |
| 2019年12月10日(火) | 第二回説明会 @NII |
| 2019年12月15日 | タスク参加登録開始 |
| 2020年 02月15日 | データセット配布開始* |
| 2020年 03月16日 | 開催中止 |
| 2020年 04月23日 | 第1回オンライン説明会 |
| 2020年 04月30日 | |
| 2020年 05月07日 | Dry Run 開始 ※目的:参加者からエラーを報告してもらう |
| 2020年 05月27日 | 第2回オンライン説明会 |
| 2020年 06月27日 | 第3回オンライン説明会 |
| 2020年 06月30日 | Dry Run 終了 ※目的:参加者からエラーを報告してもらう |
| 2020年 07月01-07日 | Leader Boardの一時停止期間(データの修正期間) |
| 2020年 07月12日 | |
| 2020年 07月31日 | タスク参加登録締切 |
| 2020年 07月31日 | 本テスト終了 |
| 2020年 08月04日 - 10日 | 参加者による評価期間 |
| 2020年 08月11日 - 14日 | 評価結果の集計期間 |
| 2020年 08月15日 | 評価結果の参加者への返送 |
| 2020年 08月下旬 | 第四回説明会(報告会) |
| 2020年 09月01日 | タスク概要論文一部公開 |
| 2020年 09月20日 | NTCIR-15タスク参加者論文(ドラフト) 提出締切 |
| 2020年11月01日 | NTCIR-15タスク参加者論文・タスク概要論文 提出最終締切 |
| 2020年12月8-11日 | NTCIR-15 カンファレンス & EVIA 2020 (NII, 東京) |
Team
Organizers

Kenichi Yokote
HITACH

Keiichi Takamaru
Utsunomiya Kyowa University, Japan

Yuzu Uchida
Hokkai-Gakuen University, Japan

Hokuto Ototake
Fukuoka University, Japan

Hideyuki Shibuki
National Institute of Informatics, Japan

Sasaki Minoru
Ibaraki University

Yasuhiro Ogawa
Nagoya University

Akiba Tomoyoshi
Toyohashi University of Technology

Yoshioka Masaharu
Hokkaido University

Teruko Mitamura
Carnegie Mellon University, USA

Madoka Ishioroshi
National Institute of Informatics, Japan

Adviser

Satoshi Sekine
RIKEN

Noriko Kando
National Institute of Informatics

Kenji Araki
Hokkaido University

Tatsunori Mori
YOKOHAMA National University


